The “I” in ACID — Weak Isolation Levels
ACID is an acronym for Atomicity, Consistency, Isolation and Durability. ACID compliant databases provides
- Atomicity, if it has the ability to group multiple statements together and execute it as if it were executing a single atomic statement. There can only be two outcomes for such an execution, either all the statements execute successfully or all statements fail. This atomic execution is called a transaction.
- Consistency, if it can uphold your data invariants. This is highly dependent on the data modelling. If the modelling takes care of defining these invariants using the integrity constraint mechanisms that the database provides, a consistent (as per ACID) database ensures that those invariants hold true always.
- Isolation, if the database guarantees that concurrent transactions don’t affect each other.
- Durability, if the database ensures that every transaction that is committed are not lost. Absolute durability is not possible of course (total failure scenarios), but a durable database ensures that it safeguards against known patterns of failures.
In this post, we will pivot around Isolation. Absolute isolation is possible if all transactions are serializable i.e the final outcome will be the same as if all transactions were executed sequentially. The simplest way to achieve serializability is to force all transactions to execute on a single thread. This would, of course, incur a performance penalty and wouldn’t be suitable for real world applications. Before we look at better ways to achieve serializability, we will look at some of the weaker isolation levels that databases provide.
Why do we need isolation at all ?

Here, user 1 sends an email to user 2. Sending an email involves adding an entry for the new email for user 2 and incrementing the unread count for user 2. If there were no isolation at all, there is a possibility that user 2 would see stale unread count even after receiving the new email.

This could happen because reads of un-committed records are possible. These reads are called dirty reads. Similar to dirty reads, there could be dirty writes as well, if a transaction overwrites an uncommitted value.
Read Committed Isolation
In a read-committed isolation level, dirty reads are prevented by making sure the database only allows reading committed entries.

To prevent dirty writes, every transaction can take a row level lock which will prevent any other transaction to overwrite an uncommitted value.
Dirty reads can also be prevented by having the read transaction also taking the same lock but this could really hamper performance of read heavy systems. Any long running write transaction could block the read transactions for a long time. Ideally we don’t want writers to block readers or readers to block writers.
For every row, if we store both committed as well as uncommitted versions, any reader can just use the committed version while the writer continues its transaction by working on the uncommitted version. Once write transaction is complete, the previous committed version if replaced by the new one, seemingly atomically.
Although, there is a slight overhead of storing two version of every row, it pays off because of the significant improvement in performance.
Snapshot Isolation
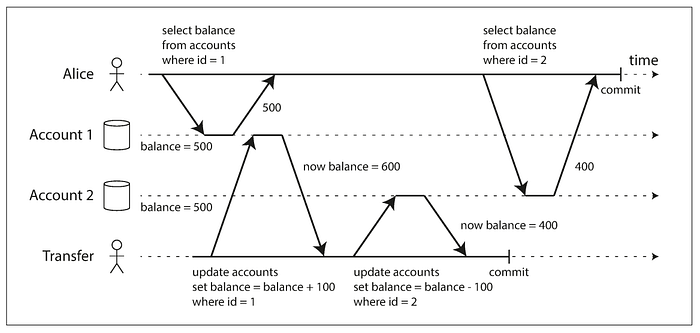
This is a perfectly valid scenario in read-committed isolation. But from a user point of view, Alice sees a total of 900 in her bank accounts while she was expecting 1000. This expectation mismatch in Alice’s read query is called read skew or non-repeatable read. If Alice repeats her first read query, she will see 600 and a total of 1000 in her two bank accounts, which is consistent. The fact that Alice found the database to be in an inconsistent state needs to be fixed nevertheless.
We want the data to not change within a transaction i.e repeatable read. To achieve this, database provides a higher isolation level called Snapshot Isolation.
To achieve repeatable read, we have to ensure that read queries return the data which was last committed throughout the duration of a read transaction. From the read-committed implementation, we have the last committed data already which we can use here. But if we have a long running read transaction, we would need more than one version of committed data. This is because there could be multiple write transactions that could complete while the read transaction is in progress.
Multi-version Concurrency Control (MVCC)
Snapshot isolation is implemented using MVCC, where we have multiple versions of a row. Every new write, carries with it, the transaction id. For every read transaction, all reads will happen on the version of the data belonging to the latest transaction lower than the current read transaction id.

Snapshot isolation did solve a lot of our issues but there are still many scenarios where it can lead to erroneous outcomes.
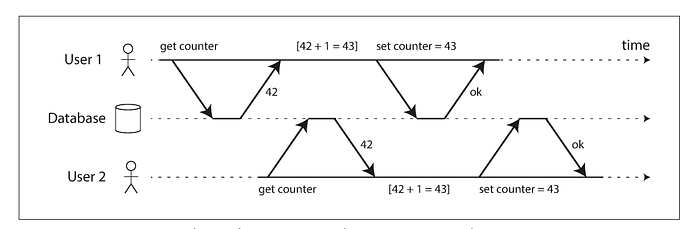
Here, the final counter value should be 44, but we lost one of the update. To achieve this, we need to make sure both these transactions happen serially. We will discuss Serializability in a future blog post.
References
- “Designing Data-Intensive Applications” by Martin Kleppmann
